
《现代电影技术》|王珏等:AI音频技术在电影对白和音效制作中的应用探究
在国家推动文化产业高质量发展的背景下,以AI大模型为代表的通用人工智能技术的发展与应用,将为电影产业带来前所未有的变革。AI音频技术通过精准模拟人声和环境音效,不仅大幅提升了对白与音效的制作效率和质量,还显著增强了影视作品的沉浸感与艺术表现力,为国产电影走向世界舞台提供了强有力的技术支撑,助力中国故事以更加生动鲜活的方式呈现于全球观众面前,是实现中华文化自信自强的重要途径之一。论文《AI音频技术在电影对白和音效制作中的应用探究》梳理和回顾了AI音频技术从20世纪50年代至今的发展历程,有助于理解当前技术的演进过程和关键节点;对AI音频制作工具进行了分类梳理,并从主要功能、代表性工具、特性及精度等维度进行了性能对比,有助于理清AI音频工具的最佳应用场景;深入分析了相关技术在语音生成、动效生成、音响效果生成等电影对白生成和音效制作中的具体应用,展示了AI音频技术在实际影视制作中的应用潜力。论文从应用角度指出了当前AI音频技术在复杂情感表达、语种覆盖范围等方面的局限性并提出未来展望,为后续研究和发展应用指明了方向。
北京电影学院声音学院教授,主要研究方向:电影声音艺术与技术、新媒体声音。
北京电影学院声音学院2023级电影声音创作方向硕士研究生,主要研究方向:电影声音艺术与技术。
AI音频技术在当前电影对白和音效制作领域备受关注且已逐步应用到实际制作中。本文介绍了AI音频技术的主要概念及发展概况,对现阶段AI音频制作工具进行了分类整理,并按照电影对白和音效制作中声音生成与声音处理两大应用场景,探讨AI音频技术在电影对白和音效制作中的应用进展与未来前景。研究表明,目前AI音频技术可用于部分场景和部分类别的对白生成,但缺乏复杂情感表达能力;在动效和音响效果生成中可完成一定的素材准备,但精确度和丰富度有待提高。在声音处理方面,AI音频技术具备较强的音频降噪及增强、对白音色替换、动态及响度控制、音色及空间处理能力,在声音编辑和预混中已得到实际应用,但尚无法胜任声音设计、混录等需要高度依赖艺术创造力的环节,暂不具备独立完成整部电影声音制作的能力。
人工智能(Artificial Intelligence, AI)是旨在研究开发能模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的一门新的技术科学[1]。广义上,AI可被理解为一切以机器为载体且能从环境中接受感知并执行行动的智能体(Agent)[2],可像人类智能一样呈现出知识推理、自然语言处理、语音识别等能力。自AI诞生以来,其始终在由弱人工智能(Weak AI)向强人工智能(Strong AI)进化,其类人性、通识性及处理跨领域、多维度任务的能力持续提高,应用范围不断拓展,从而形成了各类基于AI的新兴技术,包括AI音频技术。
AI进入音频领域可回溯至20世纪50年代,当时计算机科学的研究重心之一在于如何使机器借助语音与人类进行高效、自然的沟通。基于这一需求,语音识别与语音合成自然成为AI音频技术早期发展的探索领域。1952年,美国电话电报公司贝尔实验室(AT&T Bell Laboratories)成功研发了首个具有实用意义的AI语音识别系统奥黛丽(Audrey)。其具备针对具体个人的数字0~9的语音识别能力,通过计算机将输入的语音与预先录制的数字语音模板进行频谱特征匹配,可实现97%~99%的识别准确率[3]。1962年,IBM的John Larry Kelly和Louis Gerstman使用IBM 704计算机,根据规则预设将文字转换为语音,合成了歌曲Daisy Bell中的人声信号,首次实现了计算机歌曲演唱[4]。随后,AI音频技术的探索领域进一步扩展。1968年,美国无线电公司(Radio Corporation of America, RCA)的Dale C. Connor和Richard S. Putnam针对广播领域不同来源、类型的音频信号存在较大电平差而易导致音频失真及过度压缩的问题,提出了一种无需人工操作的自动增益控制(AGC)系统[5],探索了弱人工智能的电平及动态控制技术。1971年,B. S. Atal和Suzanne L. Hanauer进行了AI语音转换技术的初步探索,使用线性预测编码技术(LPC)实现了语音特性的改变[6]。
自20世纪70年代起,随着计算机性能的提升和数字信号处理技术的进步,AI音频技术进入逐步发展阶段。算法的迭代及优化使AI音频技术性能不断增强,初步实现了部分领域的产品化与商业化,AI音频发展来到了技术与市场的交叉点。20世纪80年代至90年代,基于规则推理的手工编程开始向数据驱动的机器学习(Machine Learning, ML)过渡,意味着AI音频技术在自动化程度、智能化水平及通用性上将迎来提升,从而可进一步拓展其应用领域。语音识别的发展较好地说明了这一点,AI语音识别技术于80年代凭借使用隐马尔可夫模型(Hidden Markov Model, HMM)取得突破性进展[7]。有别于先前依赖相关领域专家的知识和经验、通过编写硬编码规则进行语音识别的手工编程方法,HMM作为一种机器学习算法,能很好地捕捉语音信号的时变性和平稳性[8]。该模型利用大量真实语音数据进行训练,可实现更高的识别准确率。凭借这一方法,AI语音识别技术在90年代实现了以人机交互和通信为主的初步应用及产品化,出现了人机语音交互软件ViaVoice、电话自动语音识别系统SpeechWorks等代表性产品[9]。
21世纪以来,随着学习算法的改进、大数据的发展和算力的提升,AI音频技术进入深度学习(Deep Learning, DL)时代。深度学习是机器学习中一系列技术的组合[10],有别于以使用浅层结构模型为主的传统机器学习,其通过模拟人脑神经元结构形成复杂的多层神经网络模型,如卷积神经网络(CNN)、循环神经网络(RNN)、生成式对抗网络(GAN)等,令计算机构建一个包含较多计算步骤的从输入到输出的映射函数,用以处理复杂的数据或任务。随着深度学习技术的真正爆发,AI音频技术在语音识别、音频处理及音频生成等领域开始取得显著成果。2011年,结合深度信任网络(Deep Belief Network, DBN)的强大判别训练能力和HMM序列建模能力的AI语音识别技术,在大词汇量连续语音识别(LVCSR)任务中取得优异表现[11]。2016年,DeepMind发布基于深度神经网络的音频生成模型WaveNet,在文本转语音(Text⁃to⁃Speech, TTS)任务中表现优异,取得了AI语音合成技术的重大突破,同时亦为音乐、音效生成领域提供了新范式[12]。自2019年开始,随着深度学习方法的深入应用,AI音频技术在音频分析、处理与生成中均展现出了惊人突破与强大潜力[13],步入高速发展阶段。此外,自动化机器学习、大型预训练模型、多模态数据处理、模型压缩以及云计算等技术的发展,使AI音频技术开始真正深入融合到影视、游戏、音乐、通信、教育以及医疗等各行业中。
音频制作工具发展至今,已具备较为坚实的自动化水平,在某些制作环节已能极大减轻人工负担,提高工作效率。在此基础上,基于机器学习和深度学习技术,AI音频技术显著提高了音频制作工具的智能化水平,一系列AI音频制作工具应运而生,覆盖从音频分析、处理到生成的各领域。本文将现有AI音频制作工具分为分析、处理与生成三大核心类别,并根据具体任务需求,进一步细分为多个子类别。需要说明的是,音频分析往往是处理和生成的基础或前置步骤,而音频生成也涉及一定的处理过程,因而三类工具在实际功能上有所重叠,但它们在目标制作任务上有着明显不同的重心和倾向。
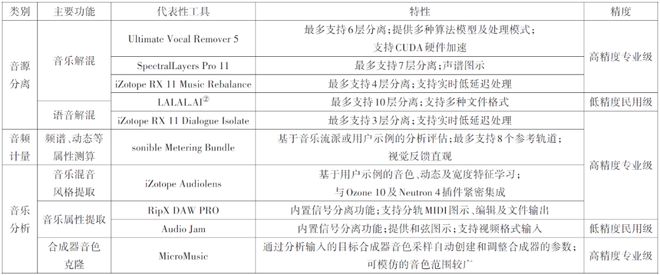
AI音频分析工具(表1)侧重于对音频进行解析与特征提取,目前主要用于完成诸如音源分离(Audio Source Separation)①、音频计量、音乐分析等制作任务;AI音频处理工具(表2)倾向于对音频信号进行实际调整,当前主要用于完成音频降噪及增强、音色转换、动态处理、频率处理、空间处理等制作任务;AI音频生成工具(表3)则注重创造新的音频内容,根据用户所输入的文本、提示词(Prompt)、视觉内容信息或条件参数输出音频,现阶段主要用于语音、音效及音乐生成。目前,AI音频处理工具多以面向专业音频工作者的高精度专业级工具为主,分析类工具和生成类工具则涵盖了从面向普通消费者及用户生成内容(UGC)生产者的低精度民用级至高精度专业级的广泛范围。其中,低精度民用级工具的应用形式以网页及桌面应用程序为主,高精度专业级工具则以数字音频工作站(DAW)及非线性编辑系统(NLE)插件为主。表1至表3从主要功能、特性及精度三个维度对上述三个类别中较具代表性的工具分别进行了整理分析。
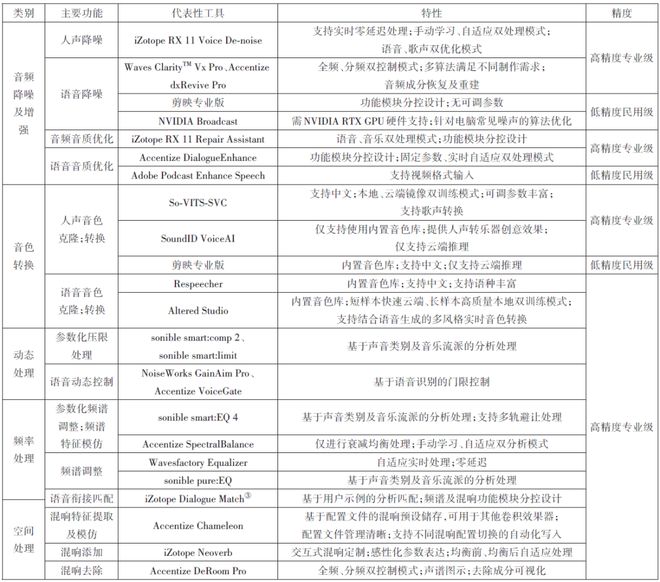
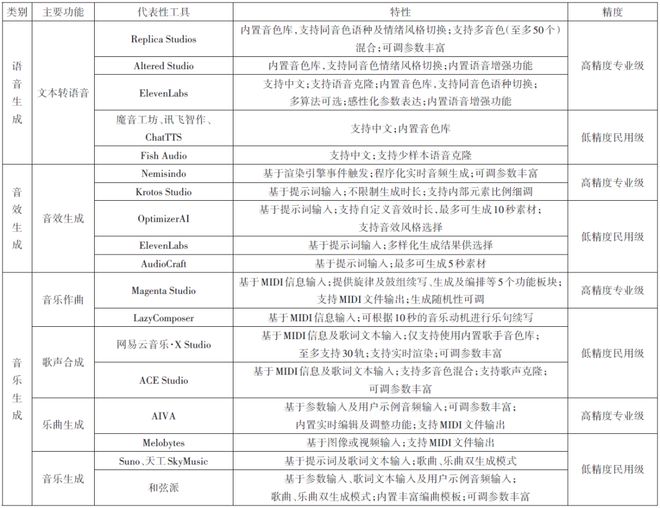
在电影对白和音效制作领域,AI音频制作工具的引入为制作手段和创作方法提供了新的可能。由表1至表3可知,以弱人工智能为主的AI音频分析工具及处理工具通过大规模数据训练使计算机完成特定任务,现阶段可辅助制作者完成降噪、基本动态控制等重复劳动,提高制作效率;以强人工智能为主的AI音频生成工具正逐步取得突破,在对白、音响效果等电影声音内容生成中的应用已有所进展[14]。
对白(Dialogue)是电影声音中具有重要叙事功能的元素,目前对白语音主要通过同期拾录或自动对白替换(Automatic Dialogue Replacement, ADR)获得,利用AI音频技术生成对白是电影对白制作的一种新思路。现阶段AI语音生成技术在电影对白制作中的应用以TTS为主,即以台词文本作为输入模态,通过文本前端模块将原始文本转换为字符或音素,再通过AI音频工具内置的声学模型或对特定演员进行音色克隆所得到的声学模型转换为声学特征,最后借助声码器转换输出为具有自然语音特征或特定人语音特征的语音音频信号。基于AI的TTS语音生成技术较传统TTS技术而言,在语音自然度及流畅度、情感表现力和音色定制能力等方面已取得显著进展,但对于高精度的电影声音制作而言,利用该技术直接生成对白语音仍有一定难度。一方面是由于现阶段的AI语音生成难以实现电影对白高度复杂的情感表达并与视觉内容同步,另一方面则是生成语种的覆盖范围有限。声音的情感表达是目前AI音频生成的难题,现有的AI音频工具提供了简单的情绪选项,可以在愤怒、愉悦等情绪范围内进行选择,但这些参数的分类过于粗略,尚无法对应于电影对白中复杂细腻的情感变化。由于情感的主观性特征,对复杂情感的声音特征标注也是目前情感计算领域的一个难题。但这并不意味着目前AI语音生成技术在电影对白生成中毫无用武之地,在某些应用场景中,该技术仍有一定的应用可行性与发展前景。
在真人电影的拍摄过程中,演员的表演实际构成了一个高度集成的视听同步序列,通过TTS技术生成与已拍摄内容视觉严格同步的对白语音仍十分具有挑战性。现阶段的AI语音生成工具虽提供节奏、随机性、表演风格等选项供用户调整,但生成的语音仍难以与视觉内容保持时间上的同步及情感上的契合。然而,电影中往往存在一些无需严格与视觉形象同步的真人角色语音,包括但不限于旁白、解说、独白、群杂以及收音机或其他媒介播放出的语音,这为使用AI音频技术进行语音生成创造了条件。例如,当需要根据影片内容录制一条语义明确的英文新闻播报时,可借助Altered Studio工具,在TTS模块中输入台词文本,并在其内置的模型库中挑选性别、年龄及口音符合要求的模型,最后选择新闻播报表演风格进行生成。
在动画角色、科幻角色或数字人等虚拟角色的制作过程中,若采用先录制对白后制作画面的先期录音工艺,上述AI语音生成方法便不受视听同步问题的困扰,可用于全部对白生成。制作者可在AI音频生成工具中输入台词文本,并在语音模型库中选择符合角色形象的模型进行语音生成,随后将语音输入转换为逼真的面部动画。例如在Replica Studio的Voice Director模块中,制作者可根据角色需要在其内置的Voice Library中选择合适模型,或通过Voice Lab模块进行自定义音色混合得到定制化语音模型,随后输入角色台词文本,选定表演风格及调整音调、节奏,最后进行对白语音生成并完成视觉内容制作。在这类语音驱动的虚拟角色制作场景中,随着AI语音生成技术的持续进步与优化,采用这一技术进行全部对白语音生成展现出一定的可行性与潜力,但目前同样面临着支持语种有限及表演情感难以调教的应用障碍。
动效指影片中由角色动作引发的音响效果,通常采用拟音(Foley)方式制作。目前的拟音方法主要包括两种:一种是由拟音师手工进行拟音;另一种则是基于采样和合成技术利用软件生成符合用户需求的动效,如UVI Walker、UVI Unlock、Krotos Studio Pro等。二者均需依照视觉线索进行人工制作,且需花费时间和精力进行道具或样本选取、拟音表演及录音等。
利用AI音频技术进行动效生成的技术路径可从视频和文本两种输入模态分别考虑,其中以视频模态输入的AI动效生成可基于数据驱动与规则建模来构建不同视觉线索与声音的映射关系,并利用数据驱动实现视听时序一致,以智能化拟音技术解决视觉与声音的同步性以及内容一致性的问题[15]。近年来,国内外均有相关研究进展,例如Ghose等提出的FoleyGAN[16]、刘子航等[15]提出的视听同步的细粒度脚步音效合成方法等。目前,此类技术对制作以脚步声、摩擦声为代表的数量多、重复性强且要求视听严格同步的动效具有一定应用价值,但在视听匹配度方面无法很好地满足电影声音制作的高标准需要,有待进一步发展和优化。以文本模态输入的AI动效生成则以制作者在生成工具中输入提示词来生成音频,比较适合生成单个点动效,例如在ElevenLabs的Text to SFX板块中键入提示词“typing”生成敲键盘的声音,再进一步通过描述细节的提示词来微调结果以完善声音,如“A person typing on a keyboard in the office”,最后在多个生成结果中选择合适的素材加以编辑使用。该方法一定程度上可减少道具或样本选取、拟音表演等工序,但无法精准控制变量或参数值,导致生成音频的可控性及稳定性较差,需反复调整提示词并筛选生成结果。总体而言,现阶段AI动效生成难以作为高质量工具直接投入应用,但为电影拟音制作提供了新的方法和可能性。
音响效果制作是电影声音后期制作的重点之一,对于一般效果而言,目前主要来源于素材库或根据影片需要专门录制,特殊音响效果则可能在此基础上通过数字音频信号合成等方式进行补充。AI音响效果生成与AI动效生成的方法基本一致,同样可在ElevenLabs、Optimizer等工具中输入文本提示词以获得目标素材,并做进一步微调和筛选。音响效果相较于动效而言,在制作上往往更为多元、复杂,且时常需要多声道素材,这就进一步暴露了某些应用障碍。例如,模型无法根据输入信息准确捕捉并表达制作者的创作意图,训练数据不充分或呈长尾分布状态以及生成的音频结果技术指标不足等。随着AI音频技术自动化和智能化水平的提升、训练数据的不断积累及自我强化机制的逐步构建,利用AI音频技术进行音响效果生成或将开辟出全新的智能化电影音效制作流程和创作思路。
在电影声音后期制作中,常常需对以语音信号为主的各类音频信号进行降噪处理。AI音频降噪技术在传统音频降噪技术的基础上,引入了机器学习和深度学习技术,在音频降噪及增强的效果上实现了飞跃,进而更好、更智能地提高音频的信噪比并保留其自然度。当前,这一技术在电影声音制作中已得到广泛应用,iZotope RX 11、Accentize dxRevive Pro以及Waves ClarityTM Vx Pro等主流语音降噪工具均采用了AI音频降噪技术,具备更强的非线性拟合能力,可对噪声进行自适应处理。AI音频增强技术可通过语音增强算法对音频信号进行重构与恢复,显著提升音频降噪的性能极限,例如使用Accentize dxRevive Pro中的EQ Restore算法处理演员使用手机或其他民用设备补录的低音质对白,之后进行频谱再生及均衡调整,从而达到电影声音的音质要求,为手机补录台词或历史音频资料等技术指标不合格的素材提供了可行的利用途径。
在电影声音后期制作中,往往需要通过ADR对技术或艺术上效果不理想的同期声加以替换。除此之外,独白或旁白、动画片制作、多语种译制等也常需要进行ADR。在实际制作中,ADR过程经常面临诸多难题,如演员因各种原因无法到录音棚录音、单演员为多角色配音易出现音色重复及形象不匹配等。面对这些难题,AI语音转换(VC)技术凭借优秀的音色模仿能力及语音自然度为制作者提供了新的解决方案。
早期的语音转换技术一般通过统计学方法建立模型,由于面临模型泛化能力不足的问题,转换后的语音缺失细节、不够线]。AI语音转换技术引入深度学习等方法,通过训练神经网络(Neural Network)以模拟不同的声音特征,从而实现将源人物语音的特定信息转换为目标人物语音,同时确保其他属性不变[18]。相较于基于统计建模的语音转换技术,AI语音转换技术具备更强的模型泛化能力,尤其当目标语音数据集质量高、时长足时,转换结果更为真实、自然。其次,通过使用不同数据集训练不同的模型,可克隆某一特定人声,使得AI语音转换技术具备较好的定制能力,可更高效便捷地完成某些ADR任务。此外,AI语音转换技术还极大拓展了单一配音演员的音色范围,提高了影片配音及多语种译制效率,降低了人力、时间及经费等成本。以下根据电影对白制作中的不同需要,简要介绍AI语音转换技术的实际应用可能。
借助AI语音转换技术克隆某人音色,可高效解决以往制作过程中的时间和档期不便,并提供新的创作方法。例如,在So⁃VITS⁃SVC中输入刘德华年轻时总时长30分钟以上的高音质切片语音数据集,选择编码器生成模型配置文件,随后选择F0预测器(F0 Predictor)并调整Batch Size、Learning Rate等各项超参数进行音色模型训练,得到音色相似且咬字清晰的理想模型后,在推理界面加载该模型及其配置文件,输入待替换的语音音频进行音色替换,便可实现对年轻刘德华音色的克隆。当前,利用AI语音转换技术进行特定人的音色克隆已取得一定成果,例如Respeecher公司运用AI音频技术为电视纪录片Goliath制作了威尔特·张伯伦(Wilt Chamberlain)的解说语音[19],也成功为网络短片In Event of Moon Disaster(2019)制作了美国前总统理查德·尼克松(Richard Nixon)的演讲语音[20]。但该技术的应用仍存在一定障碍,例如,满足电影声音高精度要求的目标音色模型需通过音质高、时长足的数据集训练获得,而待替换的语音音频需满足各项音质标准,提高了AI语音转换技术的应用门槛。随着预训练模型的自监督学习、小样本学习及跨语言多领域适应能力的提升,AI音色克隆的数据集成本将进一步降低,能在减少对数据集依赖的同时提升其性能。在未来的电影对白制作中,可在获授权情况下存档备份演员的优质音色模型,以便后续应用于其他项目的制作。
运用AI语音转换技术,制作者可通过AI音色替换工具中的多元化音色库极大地扩展单个配音演员的音色范围,从而使“一人分饰多角”成为可能,大幅提升ADR工作的效率与灵活性。例如,当需要为中文影片做英语对白译制时,可通过Altered Studio的Voice Morphing模块输入单个配音演员录制的多角色英语对白,并在Voice Library中为不同角色选择匹配的音色模型分别进行语音转换,从而大大优化影片的译制成本。当前,大多数AI语音产品,如Altered Studio、Respeecher、ElevenLabs等,皆为用户提供多元丰富的音色库,SoundID公司的VoiceAI则可将其AI语音转换技术及音色模型集成到DAW插件中,可在Pro Tools等工作站中直接应用,进一步优化文件交互流程,增强制作者的使用体验。
在传统电影声音后期制作中,动态及响度控制通常分为两部分进行:一部分是在编辑阶段对各类声音元素进行编辑处理,另一部分则是在混录阶段对各类声音元素及声音整体进行以使用动态类效果器、音量控制器为主的处理。编辑阶段动态控制的主要处理对象之一即是具有叙事功能的对白,一方面要确保其电平及响度基本达标,另一方面则要调整其内部各类信号的电平从而使听感平滑流畅。用编辑手段进行动态控制的优势在于操作/调校较为细致,但同时也要花费大量人力、时间成本;而使用传统音频压扩或响度归一技术则难以做到精细调整,无法实现只针对人声语音信号进行处理。AI语音动态处理技术能更好地对输入的音频信号进行特征提取,区分出人声信号和非人声信号并只对人声信号进行处理。例如,在DAW插件NoiseWorks Gain Aim Pro中,用户可在Ride模块中设定目标语音响度,并在Vox⁃Gate模块中设定门限处理阈值及最大衰减量,随后由AI分析并对其进行自适应响度标准化及压扩处理,辅助制作者完成对白的基本动态控制。在混录阶段进行整体的动态控制时,则可使用基于AI音频技术的动态类效果器来处理,例如在sonible smart:comp 2中选中Speech预设,后令AI对影片中的对白音频进行智能分析,形成压缩器的各项参数,辅助制作者完成对白的整体动态处理。相较于传统的动态类效果器,AI类效果器有着更好的参数自动化能力,大大减少了制作过程中对人工调整的依赖。
电影对白和音效制作中对音色的处理主要有衔接匹配、解决频率掩蔽、声音美化等几个核心目的,使用均衡器对音频的频谱结构进行调整是音色处理的主要手段。借助基于AI音频技术的频谱类效果器,可辅助制作者快速达成某些音色处理目标。首先,对于音色衔接任务,如ADR对白与同期声的衔接、无线话筒音色和挑杆话筒音色的衔接、拟音动效与同期音响效果的衔接等,传统制作方法主要是基于经验判断音色差异并使用均衡器手动调整音色,而使用基于机器学习技术的效果器进行音色衔接匹配则可简化这一过程。例如,在Accentize Spectral Balance中,制作者可在EQ Target窗口加载目标音色示例音频,再由AI进行频响特征分析,并对轨道上的待处理音频进行实时自适应处理或固定参数处理,高效完成音色衔接任务。其次,在解决不同音频的频率掩蔽问题时,可使用采用机器学习技术的效果器用于控制不同音频间的频率避让。例如制作者可在需进行频率避让的轨道上挂载sonible smart:EQ 4效果器插件,通过Group模式将需要处理的轨道进行编组,并对各轨道进行前(Front)、中(Middle)、后(Back)的纵深分层以决定均衡处理优先级;之后点击Learn All进行分析,生成各个轨道的频率处理曲线,完成多轨频率避让。若基于美化声音的目的对音频进行音色处理,则可采用Wavesfactory Equalizer、sonible smart:EQ 4等智能均衡器进行音色调整。该类效果器基于大量的优质数据样本,可根据声音类别进行智能频响调整,目前多用于基于音乐流派和乐器类别的音乐处理。
空间处理是电影对白和音效制作的重点之一,在影片进入终混前,通常需进行以使用单声道混响为主的对白或拟音的空间感统一,例如衔接ADR与同期声、同期音效与拟音动效等,从而维持叙事空间的稳定与统一。一般而言,直接使用数字单声道混响器并调整参数以模仿目标空间感难以高效地获得令人满意的效果,具备智能混响匹配功能的效果器为这一难题带来了新的解决方案。如在Accentize公司推出的Chameleon 2.0中,制作者可在Create New Reverb窗口输入携带目标空间特征的同期对白,随后由该插件基于大量训练数据的深度学习快速计算并建立起拍摄地的空间配置文件,选择Apply Now将该空间特征直接应用到待处理的ADR对白中。同时,用户也可以选择Save to Library将插件分析得到的房间脉冲响应以.wav文件格式保存到计算机本地,随后在其他卷积混响器中加载使用。在混录过程中,为了满足空间建构、效果制作以及包围感形成等多种制作需求,往往需要调动不同类别、不同声道数量的空间效果器。基于AI音频技术的空间类效果器,能根据输入信号的频谱和时间特性进行智能化空间处理,为声音制作者提供了全新的空间设计工具。如用户可使用iZotope Neoverb的Reverb Assistant功能,进行以风格(Style)和色调(Tone)等主观指标替代具体参数数值的交互式混响定制,并由AI执行自动剪切(Auto Cut)和非掩蔽(Unmask)任务,进行均衡前(Pre⁃EQ)处理和均衡后(Post⁃EQ)处理以避免混响信号对干声信号造成掩蔽导致清晰度降低。目前,这类效果器主要用于电影对白和音效制作中的非现实空间建构,暂不适合建构需以叙事空间的真实听感为依据的现实空间。
随着AI时代的到来,AI音频技术在电影对白和音效制作领域已经迈出了革命性的一步,部分繁琐且高度依赖人工处理的环节得到了显著的工艺优化与效果提升。AI音频技术在电影对白和音效制作中的应用一方面实现了一定程度的降本增效,另一方面则赋予了创作者更多的创作手段与可能。值得注意的是,现阶段的AI音频技术仍处于以弱人工智能辅助制作的阶段,具备强人工智能属性的AIGC创作范式尚需时日。简言之,目前AI音频技术尚无法胜任声音设计、混录等需要高度依赖艺术创造力的环节,暂不具备独立完成整部电影声音制作的能力。
随着技术的不断迭代与成熟,AI音频技术在电影对白和音效制作中的应用空间无疑将进一步拓展,其效果也将持续向电影声音的高精度标准靠拢。不久的将来,AI音频技术有望在电影声音制作领域发挥更为关键的作用,其智能化与高效化特征,将助力电影声音制作的工艺变化,深刻改变并推动电影行业的创新发展,这一变化趋势值得我们持续关注与探索。
[2] 斯图尔特·罗素,彼得·诺维格.人工智能:现代方法(第4版)[M].张博雅,陈坤,田超,等,译.北京:人民邮电出版社,2022.
[17] 杨帅,乔凯,陈健,等.语音合成及伪造、鉴伪技术综述[J].计算机系统应用i.csa.008641.
